
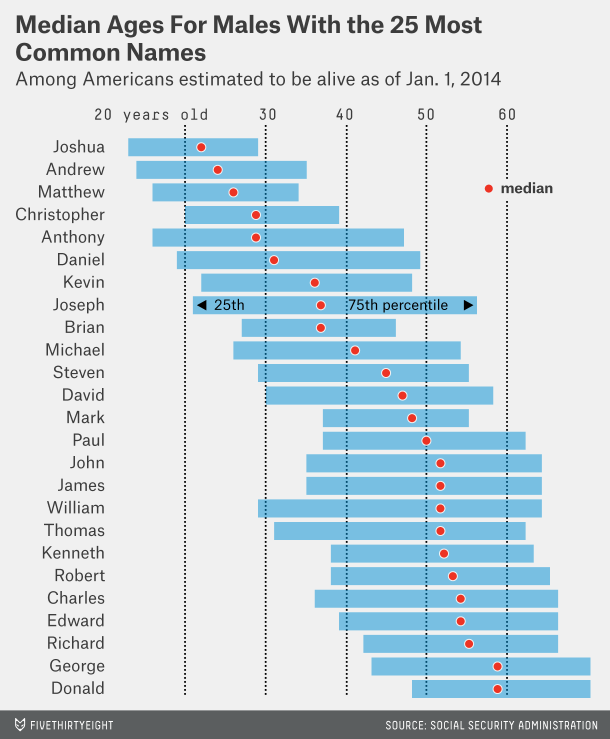
An interesting article came out on FiveThirtyEight called How to Tell Someone’s Age When All You Know Is Her Name. Based off of only a name, you could make a pretty good guess as to when they were born. It was particularly cool read given that I had actually been going through the same dataset myself.
My research had to do with the name of transgender men. I kept seeing the same names popping up, and I wanted to know whether:
- The names reflected their popularity at their time of birth.
- The names reflected their popularity at the time of their selection.
- The names reflected their popularity among their peers.
This wasn’t for academia or anything; I just wanted to know for myself. I decided that I would answer this by seeing what the most popular names were for trans men, and compare that with the popularity of those names with the general population over time.
The first step was to figure out what the most popular names were. There’s a blog with posts from the trans male diaspora where first names are often mentioned. So I wrote some software to take a peek at the names being used. I utilized a database of names from the Social Security Administration to pick out first names from the noise. The results were interesting.
The software was written in two parts using Python 3.4.
Part One: Blog Scraper
import http.client
import html.parser
import pickle
class TumblrPageParser(html.parser.HTMLParser):
def __init__(self):
super().__init__(convert_charrefs=True)
self.is_caption = False
self.results = []
self.entry = ""
def parse(self, page_contents):
self.is_caption = False
self.results.clear()
self.feed(page_contents.decode("utf-8"))
return list(filter(len, self.results))
def handle_starttag(self, tag, attributes):
if tag == "div":
if "caption" in [content for attribute, content in attributes]:
self.is_caption = True
self.entry = ""
def handle_data(self, data):
if self.is_caption:
self.entry += data
def handle_endtag(self, tag):
if tag == "div" and self.is_caption:
self.results += [self.entry]
self.is_caption = False
def parse_blog(blog_url):
conn = http.client.HTTPConnection(blog_url)
conn.request("GET", "/")
response = conn.getresponse()
page = 1
while response.status is 200 and page < 2000:
captions = TumblrPageParser().parse(response.read())
yield page, captions
page += 1
conn.request("GET", "/page/" + str(page))
response = conn.getresponse()
def download_blog(blog_url, filename):
with open(filename, "ab") as output:
for page, captions in parse_blog(blog_url):
print("Processing page " + str(page))
output.write(pickle.dumps(captions))
download_blog("a-blog-name.tumblr.com", "scraped_posts.pickle")
Part Two: Name Analysis
import pickle
def load_names(year):
with open("names/yob" + str(year) + ".txt", "r") as name_file:
for line in name_file:
first_name = line.split(",")[0]
yield first_name
def load_scraped_data(filename):
with open(filename, "rb") as input_file:
while 1:
try:
for tumblr_post in pickle.load(input_file):
yield tumblr_post
except (EOFError, pickle.UnpicklingError):
break
def extract_words(line):
return line.replace(",", " ").replace(".", " ").replace("(", " ").replace(")", " ").split(" ")
def extract_names(scraped_data_file, name_year):
first_names = list(load_names(name_year))
tumblr_posts = list(load_scraped_data(scraped_data_file))
names = dict()
for counter, post in enumerate(tumblr_posts):
print("Processing Post " + str(counter) + "/" + str(len(tumblr_posts)))
for word in extract_words(post):
potential_name = word.capitalize()
if potential_name in first_names:
names[potential_name] = names.get(potential_name, 0) + 1
return names
def trans_name_popularity():
trans_names = extract_names("scraped_posts.pickle", 2013)
names_sorted_by_popularity = sorted(trans_names, key=lambda name: trans_names[name], reverse=True)
for name in names_sorted_by_popularity:
print(name + " (" + str(trans_names[name]) + " hits)")
trans_name_popularity()
The Results: Most Popular Names for Trans Men
- Alex
- James
- Oliver
- Ryan
- Jake
- Cameron
- Dylan
- Aiden
- Tyler
- Andrew
- Lucas
- Max
- Andy
- Adam
- Daniel
- Noah
- Eli
- Liam
- Sam
- Charlie
Take the results with a healthy dose of skepticism; there’s loads flawed about this approach.
The most popular baby names for 2014 were well represented in the top names for trans men. Names like Eli, Liam, Noah, Jayden, Aiden, etc. Presumably when many of them had come out. Thus you could actually make a guess as to when someone came out based off of their names.
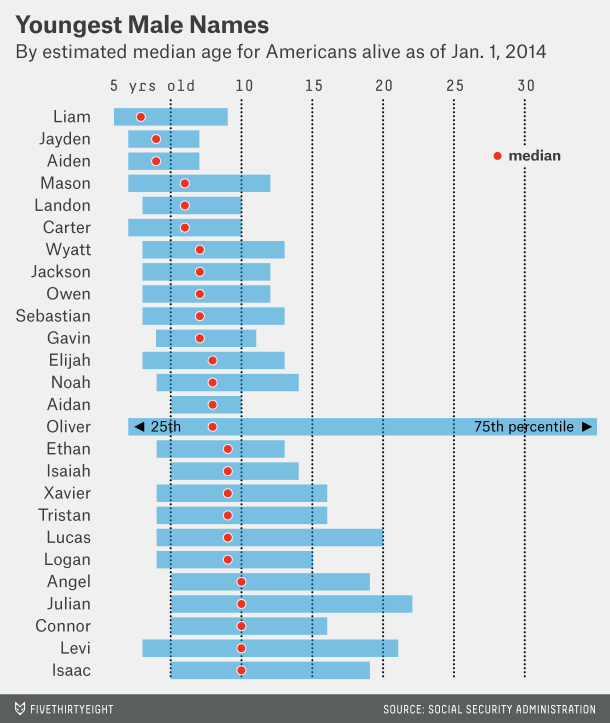
The other top names would have been the most popular around the time of birth of the individuals. So it seems to be a little bit of column A, a little bit of column B. I didn’t answer whether social networks had an influence on it. Would be an interesting question but not one I’ll explore.
It was a cool little experiment. I answered my question and deleted any data that was on my computer pertaining to this. I became uncomfortable with the idea of a blog scraper and I don’t think I’ll ever design one again.